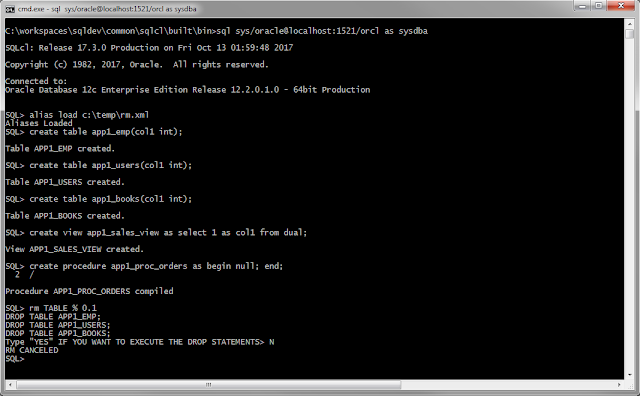
JWT Profile : Validating JWT Access Tokens In ORDS

ORDS 23.3.0 brings a new way of accessing protected resources using JSON Web Tokens (JWT). Making it much easier to integrate ORDS with OAuth2-compliant Identity Providers such as Oracle Identity Cloud Service (IDCS) Oracle Identity Access Management (IAM) Microsoft Azure Active Directory Okta OAuth0 JWT access tokens issued by Identity Providers on behalf of a user/resource owner, allow a client to access the users protected resources in ORDS. ORDS provides a new feature called JWT Profile, which defines how JWT bearer tokens can be validated for a particular REST-Enabled schema. Example JWT Profile JWTs presented as Bearer Tokens for protected resources for a particular REST-Enabled schema have to be Signed with a signature which can be validated using the schemas JWT Profile p_jwk_url Provide an audience "aud" claim which matches the schemas JWT ...